I caught myself, again, telling Claude that we don’t do it that way in this codebase.
Not the first time that week. Not the first time that day. Different repo, same correction. The kind of correction that doesn’t belong in a CLAUDE.md because it’s not really about that repo — it’s about how I work, the patterns I’ve learned the hard way, the shapes of solutions I trust because I’ve watched the alternatives blow up. But it’s also too specific to live in my global system prompt, because half of it only applies to certain kinds of services, certain teams, certain problem domains.
The agent was infinitely patient about it. I was the one running out of patience with myself.
Your judgment lives in a layer that has no home
Your CLAUDE.md knows the conventions of one repo. Your system prompt knows you, in the abstract. Neither of them knows why you stopped trusting that ORM after the migration last spring, or why you always pull a prod data sample before sketching a backend model, or why this particular service has a query pattern that looks wrong but is actually load-bearing for a reason nobody documented.
That stuff lives somewhere. For most of us, it lives in our heads. And it leaks — because every new agent session starts from zero, because the corrections you give the agent are exactly the corrections you used to internalize through reps, because you’d rather retype an instruction for the fifth time than build a system to remember it for you.
There’s a layer between the repo and the person where most of a senior engineer’s actual judgment lives. The investigation patterns that work across services. The bug classes you keep seeing in your team’s code. The query you wrote three weeks ago that nothing remembered. Almost nobody is engineering that layer deliberately. The whole AI tooling conversation is about giving the agent more context. Almost no one is talking about the engineer keeping their own.
This is the layer worth engineering. The question is where.
Some of this already existed
I’ve kept a dev journal for years. I wrote about it in What I’m Doing to Not Become Irrelevant — daily notes on what I worked on, what broke, what decisions I made. As a self-reflection tool, it’s solid.
Around it, other practices had grown. Deep-dive docs when I picked up hard problems. Spec-shaped files before I let myself code. Short retrospectives on how the spec held up to reality. Three or four practices, all separate, all useful in isolation — and none of them feeding the work itself, only my reflection on the work.
What changed wasn’t that I started writing things down. I’d been doing that for years. What changed was realizing the same artifacts — extended slightly, structured deliberately, made readable by an agent — could stop being a record of past work and start being an active substrate for current work. The foundation was already there. It just had one job.
Once I saw that, the rest followed. If the artifacts were going to feed the work, they needed somewhere to live where the agent could find them and the next stage could pick them up. Not a folder I’d drop notes into. A structure with rules about what goes where, named consistently, organized so a triage on Tuesday could read what a post-pr review wrote three weeks earlier. The journal taught me that writing things down was worth the friction. Building the hub was about making the things I’d written down do something for me beyond reflection.
The hub is a git repo. The structure is the argument.
The git repo part is boring. What makes it work is what flows through it.
The submodules are the actual work repos — the services I ship into at my job, pulled in as git submodules so the hub can cross-reference live code without copying it. The artifacts are markdown files with structure, named for the linear ticket they belong to, organized so the next stage can find them.
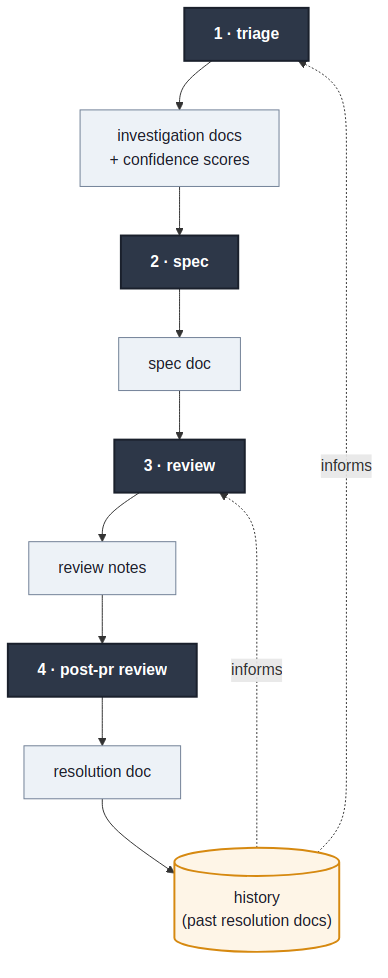
The repo is the persistence layer between stages of an engineering loop that, without it, would be stateless.
triage <linear-issue-id>
The one that changed the most about how I work. It pulls the ticket, asks clarifying questions, then investigates in stages.
First pass is code-only: trace the relevant logic through the submodules, build an initial hypothesis. Second pass is data — Postgres read replica, gcloud logs, Datadog where it makes sense. The first-pass hypothesis either survives contact with reality or it doesn’t. Most of mine don’t, fully.
Then a proposed solution, scored 0 to 10 on confidence, separately for the diagnosis and the proposed fix. They fail differently; conflating them hides where the uncertainty lives. For bugs, the proposal splits in two: the immediate action (often a data fix or a manual op to stop bleeding) and the long-term solution.
Each stage writes its own markdown file. Data and code references in one. Problem statement and root cause in another. Solution and confidence breakdown in a third. The agent asks me questions, I push back. The score is a conversation seed, not a verdict.
spec
After triage, I write the spec. Investigation produces it. I’ll come back to why this inversion matters.
review
Same review command for my code and for teammates’ PRs. Same rules, same checks. The moment I have one set of standards for code I wrote and another for code I’m reviewing, the standards are theater.
It checks against the spec, against team conventions, against the project’s history of past mistakes. The last part is the one I care about most: searching past resolution docs for shapes we’ve seen before. For history search, I’m currently using ripgrep. I’ll come back to that too.
post-pr review
After the PR merges, this runs and produces a resolution doc. It diffs what I planned in the spec against what shipped, pulls in PR comments, and writes a short reconciliation.
The artifact I undervalued for years and now consider the most important one. Specs lie about what was built. The reconciliation doc tells the truth. When the next triage looks at history, it’s the resolution docs that catch the patterns.
weekly review
Runs every Friday. Reads everything I generated that week, distills it into themes, recurring problems, decisions worth remembering. Also the doc I lean on for 1:1s and performance reviews. Closes a loop the rest of the system would otherwise leave open: artifacts feeding back into how I think about my work, not just into the next ticket.
The more detailed the spec, the more it drifts
I want to call this out on its own because it’s the strangest thing I’ve learned from running this for a while.
The detailed upfront specs I used to write — the ones I felt best about, the ones that looked most professional — drifted from what actually shipped more than the looser ones did. Not less.
The reason is obvious in retrospect. Detailed upfront specs are confident guesses about a problem you haven’t investigated yet. Every concrete claim is a claim that has to survive reality, and the more of them you make before reality has a vote, the more turn out to be wrong.
A loose spec is just guesses with the honesty to look like guesses. A detailed upfront spec is guesses cosplaying as a plan.
Investigation produces the spec, not the other way around
The standard AI workflow goes: write a clear spec, hand it to the agent, review what it produces. That works for trivial work. It collapses the moment the problem is non-trivial, because it assumes the spec is correct, and the spec is almost never correct on the first pass.
The triage-first flow inverts this. By the time I’m specifying anything, the agent and I have already grounded the work in real code paths, real data shapes, real production behavior, real failure modes from past resolution docs, and explicit confidence scores. The spec describes what to build given what we know — not what we assumed before we looked.
The discipline echoes how good teams ship LLM features in production: you don’t trust the model’s confidence to substitute for evidence, so you build evals. Investigation-first is the same move applied to your own thinking. You don’t trust your confidence either.
I have not solved long-term memory
If I left it here it would sound like everything works. It doesn’t.
The biggest open problem is retrieval. The whole system depends on past artifacts being findable when they’re relevant. Right now, retrieval is mostly ripgrep — and ripgrep works better than it should. That’s the part that worries me. I probably don’t have enough volume yet to expose its limits.
I’ve tried chromadb, lancedb, a couple of small knowledge-graph experiments. None of them clearly beat ripgrep at my current scale. The vector results came back feeling like a search engine — close-enough matches that weren’t the right doc. Ripgrep came back feeling like memory — exact matches when they existed, honest absence when they didn’t. I’d rather be told nothing was found than be handed a confident wrong answer.
I’m also not running the full pipeline on every ticket. A copy change doesn’t need triage. A new field with no downstream effects doesn’t need a full investigation. I log them minimally because the weekly review benefits from a complete picture, but I’m not going to LARP investigation discipline on work that doesn’t need it.
Knowledge belongs in layers, and most of it is in the wrong one
The hub isn’t the lesson. It’s one instance of a lesson, which is that the discipline now is putting knowledge in the layer where it’ll actually fire.
There’s no bulletproof solution here, and I’d be lying if I said mine was one. The tools will keep changing. What stays is the question: where does this piece of knowledge belong so that the right agent in the right context can use it without me retyping it?
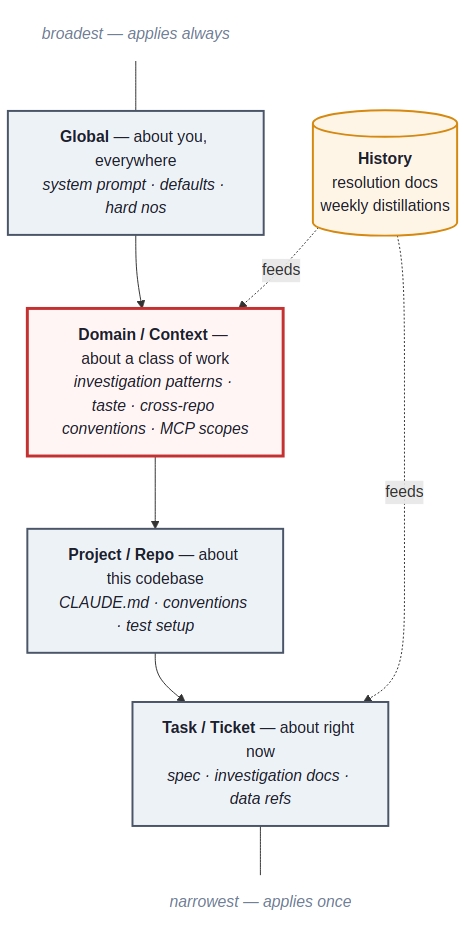
Most engineers have something working at the top and the bottom — a personal system prompt, a CLAUDE.md per repo. The middle is where the work is. It’s where your taste lives, your hard-won patterns, the corrections you keep retyping. It’s also where MCPs and skills should be scoped: attached to the kind of work they’re useful for, not loaded into every session globally or buried in one repo’s config.
The discipline is asking, every time you find yourself teaching the agent something: what’s the smallest layer this belongs in? If it’s true for one ticket, it lives in the task docs and dies with the ticket. If it’s true for one repo, it goes in CLAUDE.md. If it’s true across a domain of your work, it belongs in the middle layer — the one most people don’t have. If it’s true about you regardless of context, it goes in the global layer. Putting knowledge in the wrong layer is almost as bad as not capturing it: too narrow and you retype it, too broad and it pollutes contexts where it doesn’t apply.
History sits across all of it. Resolution docs, post-pr reviews, weekly distillations — they belong to past work but they feed every future stage. Retrieval is how history becomes context.
The reason this matters more than any specific tooling choice is that knowledge is the input that limits everything else now. The agents are fast. The compilers are fast. The deploys are fast. The bottleneck moved. What separates a senior engineer’s output from a junior’s with the same tools is almost entirely what they know and how reliably they can bring it to bear on the problem in front of them. Organizing your own knowledge — across layers, scoped correctly, retrievable later — is part of the craft now. Not a productivity hack.
Context is one slice of knowledge. Build for the whole stack.
The repo is the implementation. The argument is that knowledge is now an engineering artifact — and senior engineers either own theirs deliberately, scoped to the right layers, or accept that AI is going to hallucinate in the gaps where their judgment used to live.
We’ve spent two years getting better at giving the agent context. Almost no one is engineering the layers in between, or the history that feeds back into them. The agent has no memory. Your system prompt is too coarse. The repo file is too local. The middle is where most of your judgment lives. The history is where the lessons sit. Right now, for most people, both are leaking on the floor.
Don’t copy my structure. It won’t fit you, and even if it did it’ll be obsolete in a year. Notice that the layers exist. Notice which one each piece of knowledge belongs in. Build something — yours, ugly, evolving — that puts it there and lets it compound.
What to try Monday
Pick one piece of work you’re starting this week. Write the investigation before you write the plan. Note the code paths. Pull the real data if you can. Score your own diagnostic confidence on a scale you’d be embarrassed to fudge. Then write the spec.
Notice how much your specs were guessing before, and how much less they guess once they’re downstream of evidence.
The review process built on top of this is its own post — the part that pulls prod data correlation into the review itself, where this stops being a knowledge management story and starts being a production-engineering one. That’s next.
If your specs aren’t drifting from what you ship, you’re either not specifying enough or not shipping enough. Either way, the gap is the lesson, and right now most of us are throwing it away.